This post is a follow up to my previous look into Text Analytics. It will provide additional examples of how data can be pulled and processed in F#. I’ll also use this as an opportunity to draw more charts. For all this to happen, I’ll be doing light analysis of the full text of Mary Shelley’s “Frankenstein”.
Like last time, if you want to follow along, you’ll need to first get a free account from Cognitive Services. Then request the api access you want, for this post it is “Text Analytics”. The apikey they provide can be used in the upcoming code if you want to make your own calls. Microsoft offers a nice amount of free calls, providing plenty of room to play in the environment.
Using Paket, here is a sample paket.dependencies file.
1 | source https://nuget.org/api/v2 |
Again, here is the mostly boilerplate code. It’s where I load libraries, set the Cognitive Services apikey, and the url for the Frankenstein text on the Gutenberg site.
1 | #r "../packages/FSharp.Charting/lib/net40/FSharp.Charting.dll" |
The below code is mostly a copy of the Sentiment module and supporting functions from my previous post, modified to handle multiple documents. As promised, the modification to handle multiple documents in TextToRequestJson was an easy adjustment.
1 | module Sentiment = |
Here is where some special data knowledge is required. As is typically the case, it is important to know what the data looks like. Examining the text at the url, its nicely formatted for easy reading. The result is there are line feeds mid paragraph (I’ll need to remove those), and double spacing between paragraphs (I use these to do the paragraph splitting). Additionally, the webpage has header and footer information that isn’t the text of the book. The actual text is designated by the *** START OF... and *** END OF... lines. I use them to extract the section of book text from the page. This naive method may not be perfect, but I think it’s pretty good. It is certainly good enough for my current purpose.
1 | // Take a string and convert into list of paragraphs |
The below functions leverage the previously built utility functions to extract the raw text and transform it into paragraph form. Something kind of cool, its easy to miss, Http.RequestString grabs the plain text of url and drops it into a string. After dealing with so many verbose and heavy frameworks its a joy to use something so terse. Once the text is downloaded and transformed, I perform sentiment and word count analysis of each paragraph. I will confess, it’s temping to jam it all into a big pipeline of functions that do: url -> (sentiment, wordcount)[]. For current purposes, I prefer to have intermediate values more accessible. Also, the process is clean, but at times like these I wish F# had Haskell’s lazy infinite sequences as a built-in (see the paragraph variants below). I know F# has it’s ways to do this; but they’re not as clean as Haskell.
1 | // Take list of id/text tuples and get sentiment by paragraph |
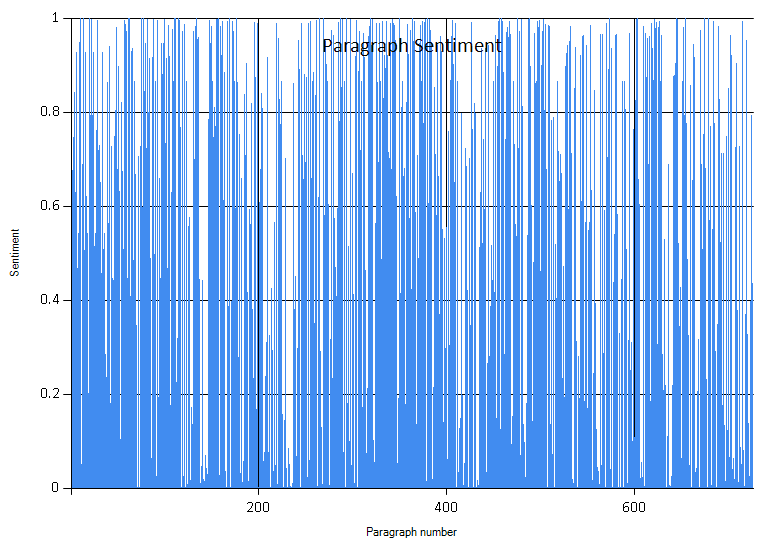
Now that I have my sentiment and wordcount lists, it’s time to do some quick analysis. Leveraging FSharp.Charting, its easy to put some simple reports together. A warning, the graphs are fun to look at, but there aren’t grand insights into the book. This is just a fun exercise. As a reminder sentiment is a scale 0 to 1, where 0 is very negative and 1 is very positive.
1 | // Sentiment through book |
This data is almost too noisy to be useful
1 | // Paragraph wordcount through book |
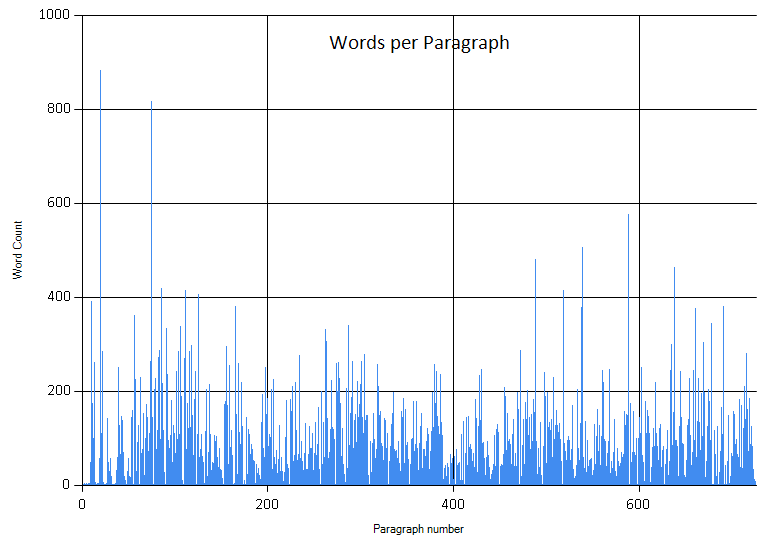
This chart shows a couple of crazy long paragraph outliers.
1 | // Histogram of paragraph sentiments |
Here we see better breakdown on paragraph sentiment.
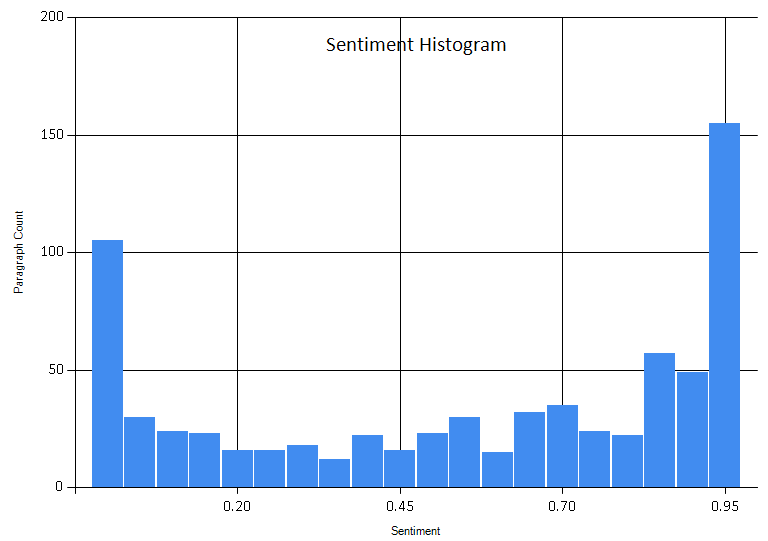
I configure the histogram to use 20 buckets. With some trial and error, this seemed like a good balance.
Note: Partially applied infix operators. For better or worse, I prefer avoiding the extra lambda syntax. If I can get away from it without obscuring intent, I do. Here is a place where I partially apply <, saving me like 13 precious keystrokes: |> List.filter ((>)500). It’s a fun trick; I think it’s more readable, but it could also be my Perl golfing tendancies emerging.
1 | // Wordcount histogram (filter out paragraphs > 500 words) |
Most paragraphs are under 200 words, with the lionshare being less than 100 words.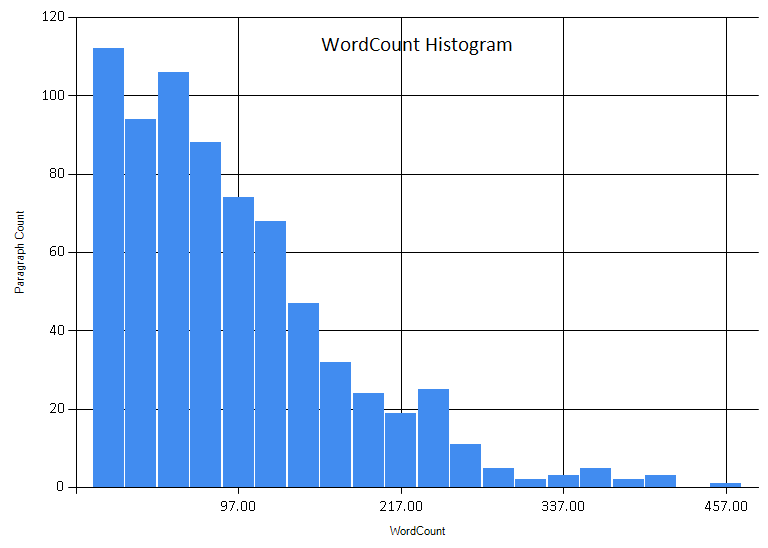
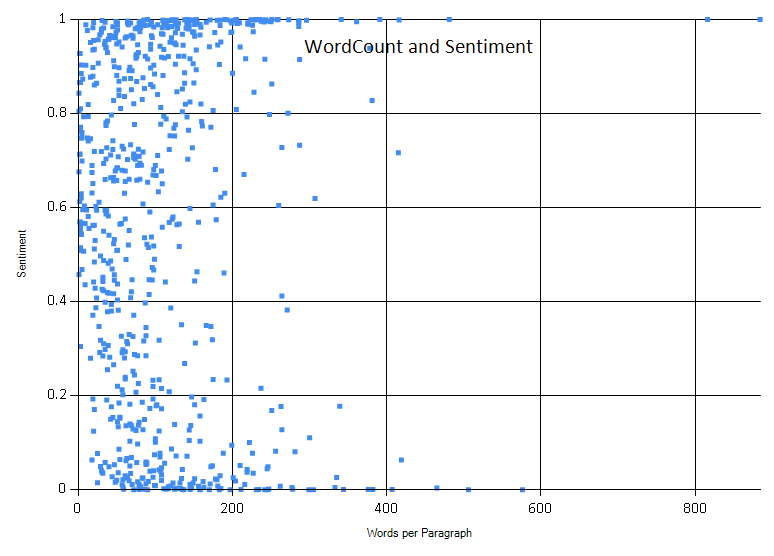
1 | // Wordcount/Sentiment graph |
Here we see if there is any trend with respect to paragraph wordcount and sentiment. I don’t really see one.
This is post is primarily about about using stock F#, and watching the data flow. With that said, I would be remiss if I didn’t mention Deedle. To do serious data analysis, Deedle is a powerful tool. It’s ability to manage and manipulate dataframes and series is extremely useful. The below tidbits don’t do the library justice, but they do provide a small taste of what can be accomplished easily.
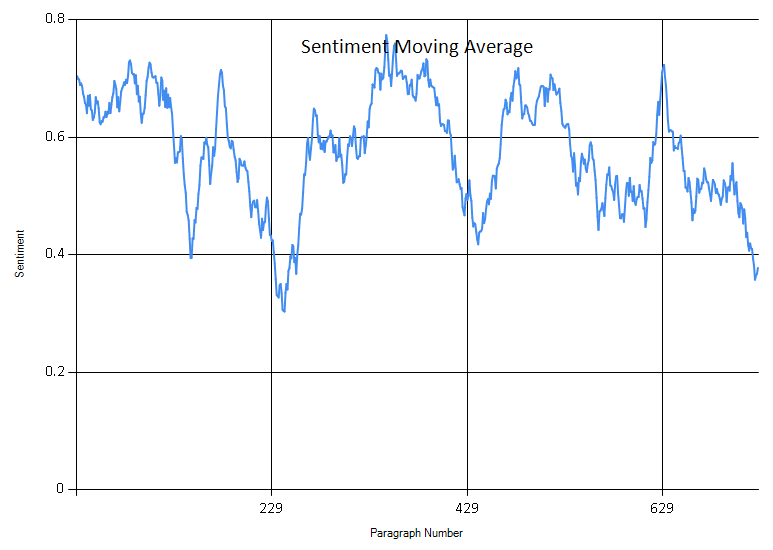
Below I convert the data into a series, allowing more advanced reporting. Then I generate a moving average, using 30 paragraphs as the window. If you remember from above, the raw data was interesting, but I don’t believe overly insightful. A moving average helps to soften peaks and display trends better.
1 | // Turn sentiment into a Deedle series |
This shows a easier to read sentiment trend. The periods of the book that use darker tones are easier to see now.
Series provide a mechanism for basic series statistics. There is no need to calculate these yourself. This is not the full range of functionality, again it is just a view into the type of calculations readily available.
1 | // Sentiment stats |
I hope you enjoyed this slightly deeper examination into sentiment analysis and F#.