The topic for today is leveraging K-Means clustering to perform simple Las Vegas hotel data analysis. This will be done using F# and Accord.NET.
K-Means clustering can be a useful tool when performing data analysis, and F# is an obvious tool for some quick transforms and reporting. This post will use customer satisfaction survey data for several Las Vegas hotels. I will focus on hotel similarity based on available ammenties. Based on this similarity I will then compare hotels against their relative counterparts. The data was obtained from the UCI Machine Learning Repository. This data is from “Stripping customers’ feedback on hotels through data mining: The case of Las Vegas Strip. Tourism Management Perspectives”[1]. If you want to follow along, go out and grab the data. Now, without further delay.
Using Paket, here is the paket.dependencies file.
1 | source https://nuget.org/api/v2 |
First, setup the libraries and defaults. k will be the number of clusters, which is 5. I’ll go into more detail later why that is my magic number. The datafile is a ; delimited file, and the CSVProvider from FSharp.Data makes loading the data easy money.
1 | System.IO.Directory.SetCurrentDirectory(__SOURCE_DIRECTORY__) |
The data is structured as multiple review instances per hotel. To get the data in the desired format, some quick transformation steps are required. For the First step, group data by Hotel into allData. Second, grab a distinct record for each hotel. For this I use (snd >> Array.head) to extract the first record from each hotel group. Third, aggregate each hotel’s specific scores so an average can be calculated into hotelScores. Finally, grab a list of hotel names for later reporting.
1 | let allData = |
There is one final transformation. The Accord.NET K-Means object expects data as an array of arrays of floats. Here I pull out the ammenities that I care about. Does it have a pool, gym, tennis court, spa, casino (you can have a hotel in vegas without a casino?), free internet, and it’s star rating. From the dataset provided, these are the most interesting.
1 | let boolToFloat x = if x then 1. else 0. |
Accord.NET makes the calls pretty easy. Setup a KMeans object with a specified number of clusters, then learn based on the data provided. Since I’m peforming analysis on existing data, I then obtain the cluster labels for my data. If the problem was a prediction problem, clusters would be the object I could use elsewhere for predicting what future hotels are similar to existing hotels. Additionally, the KMeans class provides functionality to evaluate cluster details, such as centroids and error. I’ll dig into these more toward the end.
1 | let kmeans = KMeans(k) |
Once the cluster labeling is complete I combine my earlier generated hotelScores with the cluster label for each hotel. Since I kept the data in the same order, it can simply be zipped together as a (<hotelScore>, <cluster #>) tuple.
1 | let combinedData = |
For comparative analysis, the average hotel review score for each cluster must be obtained. It is a matter of taking the newly created combinedData, grouping by cluster, then averaging the score of each hotel in the cluster.
1 | let avgClusterScore = |
This code deserves a bit of an explanation. In my defense, this is a small exercise. In production I try to avoid tuples of tuples of tuples all the way down. This is currently at the border of reasonable readability. Below is a deeper breakdown into what is going on.
1 | // Source |
Whew, now that is done. Time to see some results. The report is sorted by cluster number and hotel score (descending).
1 | printfn "%7s %-55s %5s %s" "Cluster" "Hotel" "Score" "ClusterScore" |
Based on relative ammenties (and 5 clusters), here are the results. With a small bit of code I’ve gone from data file to cluster score hotel comparisons.
1 | Cluster Hotel Score ClusterScore |
I want to backtrack now, and investigate the cluster details.
Where are the centroids for each cluster?
1 | clusters.Centroids |
What are the cluster details?
1 | clusters.Clusters |
What is the calculated error?
1 | kmeans.Error |
Taking this a little further. How many clusters should be used? What are the clustering dynamics? There are 21 hotels with 7 dimensions. My gut feeling is somewhere between 3 and 7 clusters probably makes sense. That should be enough to provide some distinction, but allow for large enough groupings to be useful. When generating the clusters, the initial centroids are random. This means the data could be clustered differently depending on starting points. To test this I’ll look at between 2 and 15 clusters. I’ll also run 100 trials per cluster size, and average the error score for that cluster. This should give a reasonable view into the clustering performance.
1 | [2..15] |
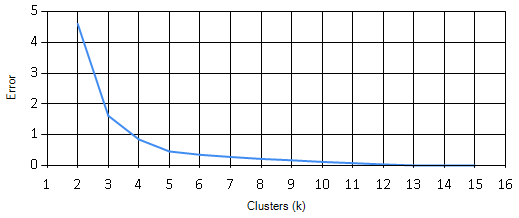
Looking at the results, error goes down as k goes up. This makes sense, with only 7 ammenity dimensions, most of them being standard, distinction completely falling off at around 12 clusters. But that’s not useful. So I can’t just take the smallest error. The most dramatic error reduction happens at 4 clusters, but the slope seems to really level off after k=5. From these results 4 or 5 seem like reasonable bets. I choose 5 because it provides a bit more separation, and it’s a prime number. :)
With all this done. I have a reasonable expectation that I’m clustering properly. I can now go back to the original report and see how similar hotels compare. This post has just been one example of how you can use K-Means clustering. I hope you found it useful. Until next time…
References
[1] ref: Moro, S., Rita, P., & Coelho, J. (2017). Stripping customers’ feedback on hotels through data mining: The case of Las Vegas Strip. Tourism Management Perspectives, 23, 41-52.